shell 命令
shell
$#:表示执行脚本传入参数的个数
$*:表示执行脚本传入参数的列表(不包括$0
$$:表示进程的id;Shell本身的PID(ProcessID,即脚本运行的当前 进程ID号)
$!:Shell最后运行的后台Process的PID(后台运行的最后一个进程的 进程ID号)
$@:表示执行脚本传入参数的所有个数(不包括$0)
$0:表示执行的脚本名称
$1:表示第一个参数
$2:表示第二个参数
$?:表示脚本执行的状态,0表示正常,其他表示错误
-----------
--- 我的理解 $@ 返回的是一个数组 $* 返回的是一个整体
当 $* 和 $@ 不被双引号" "包围时,它们之间没有任何区别,都是将接收到的每个参数看做一份数据,彼此之间以空格来分隔。
但是当它们被双引号" "包含时,就会有区别了:
"$*"会将所有的参数从整体上看做一份数据,而不是把每个参数都看做一份数据。
"$@"仍然将每个参数都看作一份数据,彼此之间是独立的。shell cat
shell
cat > ./data.yml <<EOF
hosts: 192.168.229.130
remote_user: root
tasks:
- name: test
ping:
- name: date
shell: date
EOFcentos 排查 占内存的信息
shell
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head
##这个命令会列出所有进程,并按内存使用率降序排序,最顶部的进程将是内存使用率最高的进程。%mem列显示了进程的内存使用率,%cpu列显示了CPU使用率。
## 如果你想要找到具体的进程ID,你可以使用awk来提取进程ID:
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head | awk '{print $1}'centos中,您可以使用ps命令结合grep来查询特定进程ID(PID)的信息。以下是一个基本的命令行示例,用于查询特定PID的详细信息
shell
ps -p 1290 -o comm=shell 循环
shell
for item in 1 2 3 4 ;do echo $item ; done ;
for item in {1..2};do echo "rec$item";done ;shell sed 替换
shell
# 替换文件内容
# sed -i "s/文件内容/要替换的内容/g" 文件路径
sed -i "s/http/https/g" ./2.vm权限相关 3个一组 所有者权限 所属组权限 其他人权限 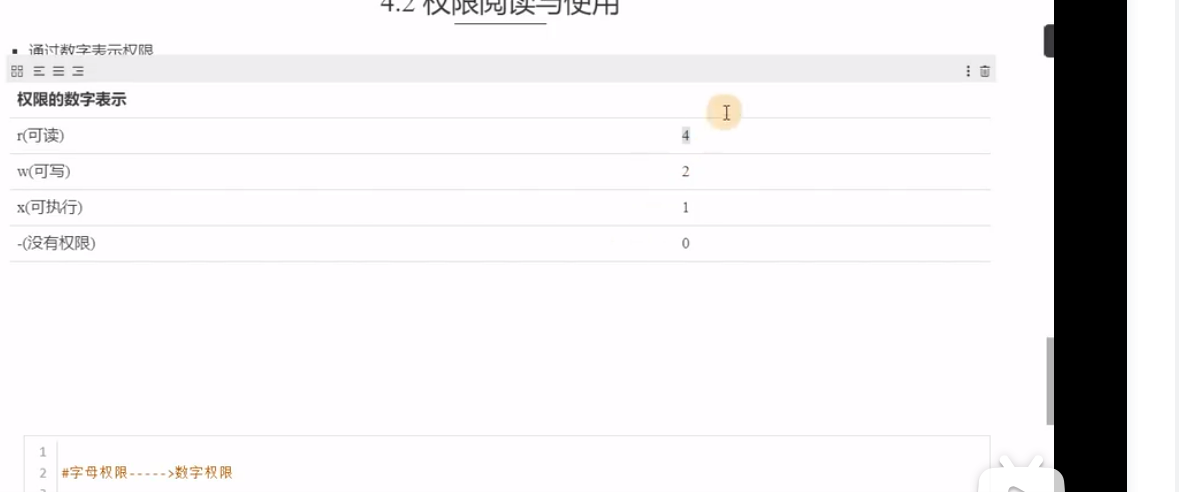
修改目录所有者
sh
chown -R 用户名 文件或目录
chown -R 用户名:组名 文件或目录
chown 数字 文件路径
chown -R es:es /opt/esbase64
sh
echo "hello"| base64内存占用率统计
shell
# linux aix 统计 内存占用率
free -m | sed -n '2p' | awk '{print "used mem is "$3"M,total mem is "$2"M,used percent is "$3/$2*100"%"}'
# 使用topas命令查看:(内存百分比=%COMP+%NOMCOMP)
https://blog.csdn.net/weixin_33095355/article/details/119432459
https://www.cnblogs.com/rusking/p/4334617.html
http://t.zoukankan.com/rusking-p-4334617.html?ivk_sa=1024320uawk
sh
# 查看 第一行
awk 'NR==1' server.log
# 查看 第一行 第一列
awk 'NR==1{print $1}' server.log
# 过滤出 或 的行
awk '/test|liu/' server.log
# awk -F ':' '第三列包含数字1开头的行' /etc/passwd
awk -F ':' '$3 ~/^1/' /etc/passwd
awk 'BEGIN{print "id", "title"}{print $1,$2}' server.log


vim
sh
vim
u 撤销
dd 删除当前行 剪切
yy 复制当前行
p 粘贴当前行到下一行 P 相反查看 磁盘存储空间
python
# 查看当前目录站的磁盘空间
du -sh
du -sh /opt
# 列出系统整体次磁盘的使用量
df -hMD5
yaml
计算 文件 md5
md5sum 文件名
----- 命令行编辑技巧
ctrl+k:把光标后面的内容全删掉。
ctrl+a:光标移到开头处。
ctrl+e:光标移动到末尾处
查看某个进程的pid
pidof nginx放行 端口 80
bash
# 放行 端口 80
firewall-cmd --zone=public --add-port=9000/tcp --permanent
# 重新载入,更新防火墙规则
firewall-cmd --reload
# # 删除
firewall-cmd --zone= public --remove-port=80/tcp --permanent获取文件的修改时间
# 获取文件的修改时间
stat --format="%y" server.log | cut -d'.' -f1
# 删除 目录下 七天前的文件
find /opt/mysql -type f -mtime +7 | xargs rm
# 把指定目录下的七天前的文件 移动到指定目录下
find /opt/test/test -type f -mtime +7 -exec mv -v -- {} /opt/test/ns/ \;nginx 截取 日志
sh
#日志截取,从总日志文件中截取昨天一整天的数据出来,并覆盖到新文件中:
cat access.log | awk '$4 >="[14/Mar/2019:00:00:00" && $4 <="[14/Mar/2019:23:59:59"' > 20190314-access.log
#将某一时间段的nginx访问日志输出到文件中
cat access.log | egrep "2020-11-04" > test.log #打印一天的日志
cat access.log | egrep "04/Nov/2020:10" > test.log #打印一小时的日志
sed -n '/04\/Nov\/2020:10/,/04\/Nov\/2020:12/p' access.log > test.log #打印任意时间段的日志
#要在文件 example.txt 中查找包含字符串 "Hello" 的行,可以运行以下命令:
egrep 'Hello' example.txt
#如果要忽略模式的大小写,可以使用 -i 选项。例如:
egrep -i 'hello' example.txt
#要显示匹配行的行号,可以使用 -n 选项。例如:
egrep -n 'Hello' example.txt
#要输出不匹配指定模式的行,可以使用 -v 选项。例如:
egrep -v 'Hello' example.txt
#要仅匹配单词的完整匹配,可以使用 -w 选项。例如:
egrep -w 'Hello' example.txt
#要统计匹配到的行数,可以使用 -c 选项。例如:
egrep -c 'Hello' example.txt