连续登录三天的数据
-- 建表语句
create table "t_login_ history"
(
id serial not null,
user_name varchar(200),
create_time date
);
comment on table "t_login_ history" is '登录历史 每天首次登录的时间';
-- 数据
insert into dev.t_login_ history (id, user_name, create_time) values (1, 'admin', '2024-08-01');
insert into dev.t_login_ history (id, user_name, create_time) values (2, 'admin', '2024-08-25');
insert into dev.t_login_ history (id, user_name, create_time) values (3, 'admin', '2024-08-24');
insert into dev.t_login_ history (id, user_name, create_time) values (4, 'admin', '2024-08-23');
insert into dev.t_login_ history (id, user_name, create_time) values (5, 'admin', '2024-08-22');
insert into dev.t_login_ history (id, user_name, create_time) values (6, 'admin', '2024-08-21');
insert into dev.t_login_ history (id, user_name, create_time) values (7, 'admin', '2024-08-20');
insert into dev.t_login_ history (id, user_name, create_time) values (8, 'admin', '2024-08-19');
insert into dev.t_login_ history (id, user_name, create_time) values (9, 'root', '2024-08-25');
insert into dev.t_login_ history (id, user_name, create_time) values (10, 'root', '2024-08-24');
insert into dev.t_login_ history (id, user_name, create_time) values (11, 'root', '2024-08-23');
insert into dev.t_login_ history (id, user_name, create_time) values (12, 'admin2', '2024-08-25');
-- 统计 连续登录三天的数据 从当天日期推算 三天前的日期 获取开始日期和结束日期
-- 查询出这个区间的数据
-- 按照 用户名分组 统计 count =3的即可
with t as (
select t2.*
from dev."t_login_ history" t2
where t2.create_time between to_date('2024-08-23','YYYY-MM-DD') and to_date('2024-08-25','YYYY-MM-DD')
)
select t.user_name from t group by t.user_name
having count(user_name) =3
;在有限内存空间内读取 超过内存空间的数据 统计 出现的次数
假设 1g内存 有一个txt 存储了40亿行的文本数据 统计每个字符串出现的次数 思路 分块读取 每次读取10兆的数据 计算次数 存储到map中
mysql 主从同步 延迟如何解决
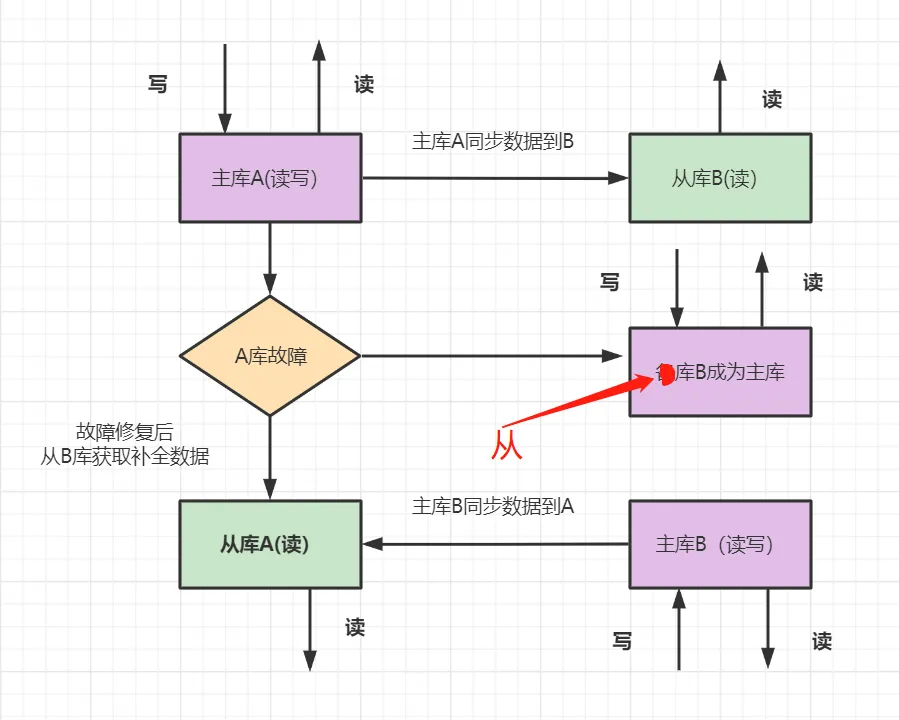
主从同步步骤 1) 主库写操作被写入到binlog 2) 从库向主库发起连接 连接到主库 3) 主库创建一个binllog dump 线程 把binlog 发送到从库 4) 从库启动后创建 一个IO线程 读取主库发送的binlog 内容 并写入到 relay log 中 (缓冲区) 5) 从库还会创建一个sql线程 从缓冲区读取binlog 从 既定位置开始读取更新事件 把更新内容写入到 从库
同步延迟原因
1) 主库和从库的机器配置差异 性能差 2) 大事务导致 主库需要执行一个较长的事务 导致同步到从库的事务被延迟 需要尽量避免大事务 尽量面 大表数据delete 分批进行 3) 从库 读的压力比较大 建议搞一主多从 分担压力 从库不需要太多 否则也会导致延迟 4) 网络延迟 丢包 导致重传 等原因
5) 数据库版本较低 建议升级 到高版本 5.7为宜 实现多线程复制同步复制 半同步复制 异步复制 1)Galera Replication 同步复制,主备无延迟 支持多主同时读写,保证数据一致性 集群中各节点保存全量数据 节点添加/删除,自动检测和配置 行级别并行复制 不需要写binlog 2) PXC 多主 强制同步 一致性保证
重复下单问题 如何
- 前端逻辑 进行防抖处理 点击按钮后则禁用按钮
- 基于 redis setnx 进入购买页面生成 一个token 点击按钮触发后 通过redis setnx 保证成功的只有一次 设置成功后则继续后端逻辑否则则判定重复下单
- 防重表 数据库建表 字段为 id token token 需要有唯一索引 进入购买页面生成 一个token 点击按钮触发后 把数据add到表中 重复下单则会有唯一索引保证不会发生
threadlocal
threadlocal 本身只能实现线程内部变量副本的存储 比如在spring的注解事务实现 也可以缓存用户登录信息 实现在代码中隐式传值,直接从threadlocal中获取用户信息 但是会有问题 在多线程环境下 子线程无法获取到父线程的值 ,此时需要使用 threadlocal的子类 InheritableThreadLocal 可以解决这个问题 也可以使用 阿里的 transmittable-thread-local https://github.com/alibaba/transmittable-thread-local InheritableThreadLocal可以完成父线程到子线程的值传递 但对于使用线程池等会池化复用线程的执行组件的情况,线程由线程池创建好,并且线程是池化起来反复使用的;这时父子线程关系的ThreadLocal值传递已经没有意义,应用需要的实际上是把 任务提交给线程池时的ThreadLocal值传递到 任务执行时。
mysql sql 执行顺序
- 权限检查
- 查询缓存
- 词法分析
- 优化器 执行
- 权限检查
sql 执行顺序
from > join > where> group by> having> selec>t distinct> order by> limit
联合索引 (a,b,c)
相当于建立了(a)、(a,b)、(a,b,c)三个索引。
-- 走索引
explain select * FROM test where a='a'
explain select * FROM test where a='a' and b ='b'
explain select * FROM test where a='a' and b ='b' and c ='c'
explain select * FROM test where b ='b' and a='a'
explain select * FROM test where b ='b' and a='a' and c ='c'
explain select * FROM test where b ='b' and c ='c' and a='a'
explain select * FROM test where a='a' and c ='c' and b='b'
-- 不走索引
explain select * FROM test where a='a' and c ='c'
explain select * FROM test where b ='b' and c ='c'
explain select * FROM test where c ='c' and a='a'删除 百万数据的方案
先删除索引 分批 批量删除数据 删除后重建索引
mysql 事务隔离级别
-- 8
SELECT @@transaction_isolation;
-- 57
SELECT @@GLOBAL.tx_isolation, @@tx_isolation;
-- 读 未提交
READ-UNCOMMITTED
-- 读 已提交
READ-COMMITTED
-- 可重复读
REPEATABLE-READ
-- 串行化
SERIALIZABLE
## 临时设置 当前会话有效
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
## 开启事务 手动
## START TRANSACTION;
## 提交或回滚
## commit rollbackredis hash slot 为什么是 16384
redis cluster 使用的是crc16算法 对16384进行取模运算 空间占用 小 2k hash 冲突的概率小 实际上主节点数是 <=1000 的 保证了分片均匀 性能和资源的平衡
zk leader 选举机制
每个节点给自己投票 同时接受来自其他节点的投票 zxid最大的当选leader ;zxid相同则看 myid 谁大则当选leader 当节点票数过半后自动当选leader 退出选举
类加载器
Bootstrap ClassLoader ExtensionClassLoader # java_home\lib\ext java.ext.dirs 系统变量指定✁路径中✁所有类库 ApplicationClassLoader
jvm 参数配置
-Xms 初始堆内存 -Xmx 最大堆内存 -Xmn 年轻代内存 -Xss 线程栈大小 128k -XX:MaxPermSize 永久代 大小 1。8后被元空间 取代 -XX:NewRatio 年轻代 老年代占比 -XXSurvivorRatio eden 和s0 s1 的占比 打印 gc -XX:+PrintGC -XX:+PrintGCDetails 查看 gc 次数 jstat -gc 进程ID delay 查看 堆栈状态 jstack pid 导出 堆栈 jstack -l > te.xt
线程池的状态
RUNNING 可接受新任务 正常处理任务 SHUTDOWN 当调用线程池的 shutdown() 方法后 不接受新任务 但会继续处理队列中的任务 STOP 调用线程池的 shutdownNow() 方法后 不再接受新任务,也不会执行任务队列中尚未开始执行的任务。 TIDYING 当线程池中的所有任务都已执行完毕,并且线程池中的工作线程数量为 0 时,线程池进入此状态 TERMINATED 线程池已完全终止
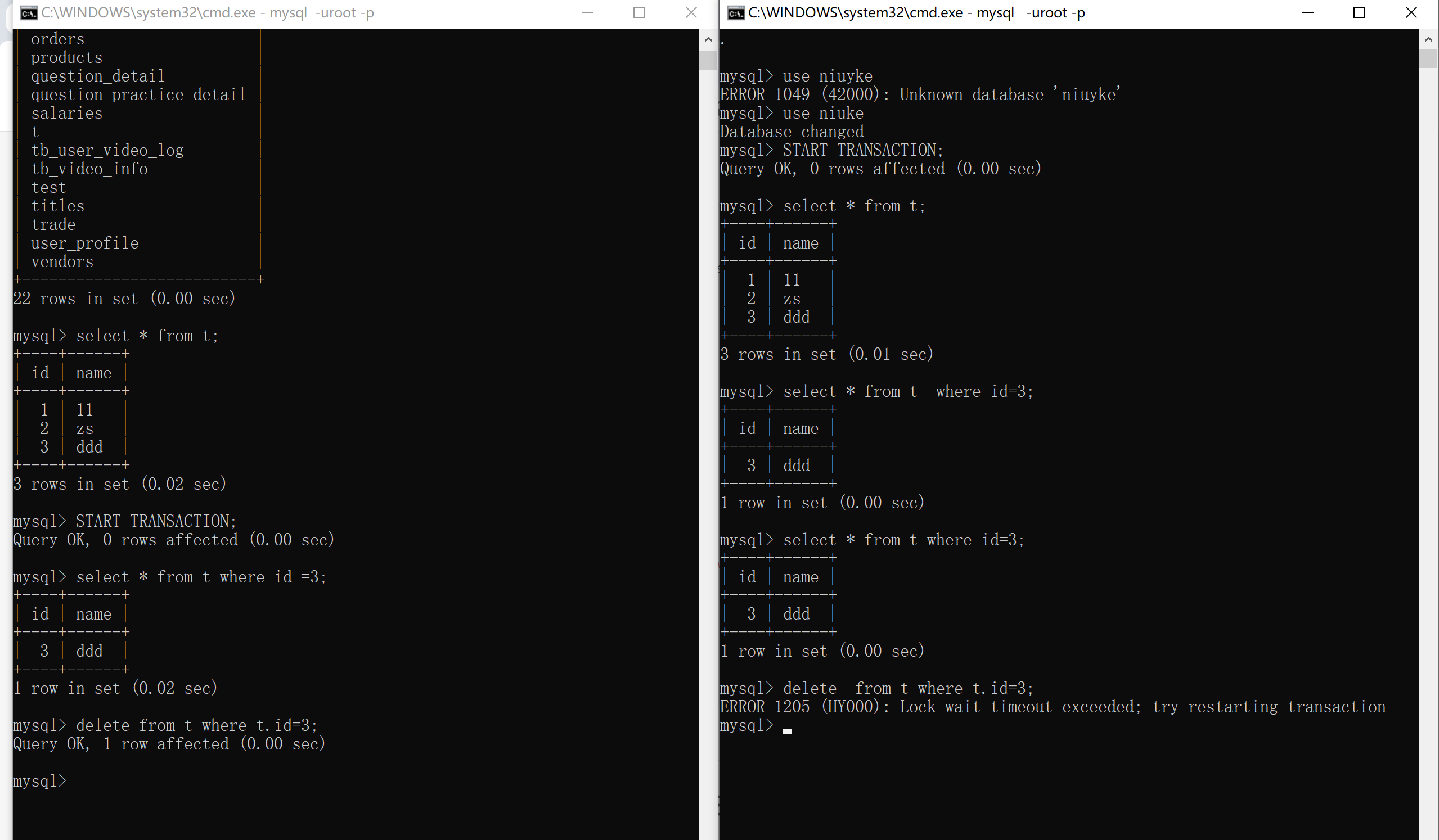
mysql delete 锁
--
两个事务A,B
A 删除记录 尚未提交事务
B 也删除同一条记录 尚未提交事务 会触发行锁 等待 锁超时问题